
Packaging


John Lewis Christmas Advert 2016
So it’s that time of year again where every Marketing nerd professional gets all excited at the launch of CHRISTMAS ADVERTS! John Lewis’ Christmas advert (the only one that anyone reallyyy cares about) made its way into our lives this week and it dawned on me that I haven’t posted any ramblings on here since my John lewis 2013 post! That’s 3 whole years ago. I’ve been too busy with a real Marketing job these days and no longer just a Psychology student pretending I knew what was going on. So I thought I’d surprise you all with another post… about this years’ John Lewis advert…Be warned, you might not like it.
Okay so this year we had a teaser, which I liked the idea of… getting everyone excited about AN ADVERT! Not a television show, not a movie… but this was an advert for an advert. If that doesn’t show that JL have stolen Christmas then I don’t know what does. The teaser featured an adorable little dog watching a girl on a space hopper (which, may I add, wasn’t featured in the actual advert; sneakily advertising two products there, nice work team). Instantly I thought, oh here we go… it’s going to be a tear jerker because they’ve included a dog. People LOVE dogs. Did you know that, more people cry during a movie when a dog dies than when a human dies? So things were looking good for JL…
However, I was bitterly disappointed with the whole thing.
For those of you who haven’t seen the advert (then I don’t know what you’re playing at) the ad features some animals bouncing on a trampoline while a sad looking dog looks at them from inside the house, Christmas morning comes and the girl in the advert runs down to her present (the trampoline), only the dog beats her to it. The point is that John Lewis sells presents that everyone will love.
I get where they’re coming from, the animals were all playing together on the trampoline and the dog was looking sadly outside the window, desperately wanting a go. But where was the build up? This all happened in one night. Not like in 2015 where the little girl waves at the Man on the Moon through her telescope for many nights before Christmas, or 2011 where the little boy is counting down the days until Christmas. For me, showing Buster eagerly wanting to play over several nights would have engaged the emotion a bit more.
It also seemed a little more materialistic than previous years. Yes okay, we all know the point of an advert is to sell the product. But often John Lewis do such a good job of enticing people into the whole story behind it – sharing presents with those less fortunate, treating your parents and others who you love instead of being greedy. To me, this just seemed like John Lewis were trying to sell the most expensive toy possible (a giant trampoline, available in 2 sizes on their website… not to mention a whole range of new animal toys).
At the end of the day, John Lewis are still awesome and I idealise their Marketing team, their adverts are so anticipated now that it doesn’t really matter if they’re good or not because people are still going to be talking about it. Even if it’s to slate the advert, they’re still using that #BounceBounce and #BustertheBoxer all over Twitter . Plus, whatever features in their advert is going to sell and other retailers are going to be quickly trying to rustle up the same products! I personally loved how I received an email from Asda a couple of hours after the advert was released. The email was titled “Something to bounce about…” and inside was their attempt to sell me their £94 trampoline! Genius!
Also, does anyone else agree that perhaps they missed a trick with the track this year? Missed opportunity for a well-loved artist who we sadly lost in 2016 to be played as the theme song? David Bowie, Prince, Pete Burns (Ok, maybe not Pete Burns…).
Sorry about the waffle. Maybe I’ll be back again in the near future, or maybe in another 3 years for John Lewis Christmas Advert 2019!!
John Lewis Christmas advert 2013
Christmas is a wonderful time for advertising!!
I absolutely love John Lewis’ adorable Christmas ads. There was last year with the Snowman wondering off to get his wife a new cosy hat and glove set to keep her warm… So cute! They even made a twitter account for the snowman which you should sooo follow because he’s so funny hehe. And of course not forgetting 2011s ad where the little boy is so eager for Christmas just to give his parents a preset. Awww!
Anyway, after the success of previous JL ads, everyone (or maybe just advertising nerds) were eager to check out what John Lewis had in store for this year..
And Ive got to say they’ve definitely won me over again. This year they focus on friendship rather than romance or family, which I think is a great idea as friends are very important around Xmas too!! Using old animators from Disney and a beautiful Keane cover from Lily Allen, they have produced a 2 minute advert of a pair of best friends – a bear and a hare!!! On the build up to winter the hare is very sad knowing his friend will be leaving him in the winter to hibernate, then when he goes it’s all sad, but the hare makes sure the bear has the best Christmas when we wakes up from hibernation. Aw it’s so cute!! JL wanted to show the importance of finding the perfect present for friends 🙂
Check it out here… Or you can catch its ‘launch’ on telly tomorrow during the X factor!!!
p-p-p-point me in the right direction
It’s amazing what people do for a little bit of cuteness 🙂
When was the last time you went to the Aquarium? If like us, the answer is an age ago, then you’re not on your own. Sunshine aquarium in Tokyo was suffering from dwindling footfall numbers and decided to do something about it. Situated less than 1km away from the nearest train station, location wasn’t the issue. People had just forgotten about it and were being distracted by all of the newer tourist attractions. So, they created the penguin NAVI app.
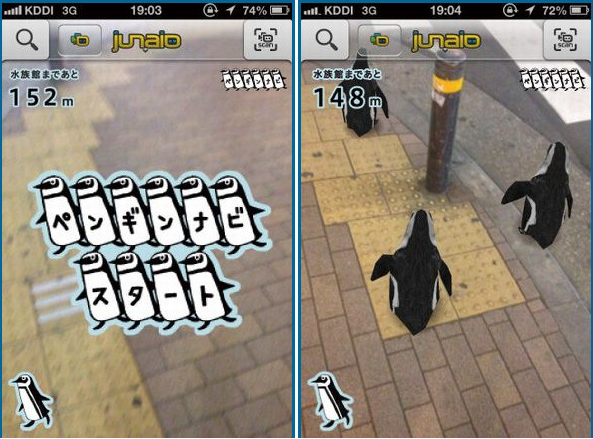
Shoppers were encouraged to download the app at the nearest station via QR codes (we know, we know. QR codes? Really? We were sceptical too, but bear with us) and once activated, an augmented reality rookery of penguins appear out of nowhere to guide shoppers along the short walk to Sunshine Aquarium.
And it seems like the cuteness factor paid off. Aquarium attendance increased 152% in the month the campaign…
View original post 29 more words
The Rice Experiment
Have you ever heard about the power of positive thinking?? If you are a positive person with happy & nice thoughts then life will give you positive things back. Whereas, if you’re a negative person, in return you will receive negativity.
Well apparently this goes for rice too.. yes, rice.
So we decided to start a little experiment in the office (just for fun, we don’t get paid for doing crazy experiments with mouldy food). This is called ‘The Rice Experiment’. Where you have two jars full of rice; the jars are identical, contain the same amount of rice, the same type of rice and so on, the only difference is one jar is labelled something positive, and the other is labelled negatively.
Here is our rice..!!

Every day (for a month) you must be nice to the ‘nice rice’ and horrible to the ‘stupid rice’. And apparently… after 30 days, the negative rice will turn mouldy!!!! So we are going to spend 30 days talking to jars of rice.
These pics were taken on day 1 of The Rice Experiment, just to show you that they are identical!


Some people think this is bonkers, some people think this will work..
What do you expect will happen?
I’ll keep you updated on what we find 😉
Just an update..
Helloooo all my lovely, loyal followers!!
Wooops.. so it seems I haven’t updated this blog in almost 2 months.. But the good news is I haven’t lost any followers yet, hehe, so thanks for sticking by ;-).
You’ve probably been wondering where I’ve been hiding, and basically I finished uni and managed to get myself a job (Go me!). Very pleased about my new job as it’s in the area that I wanted to go into, it’s a great location, everyone is very nice and I’m enjoying the work!! So anyway, as I’ve been trying to get into the swing of working 9-5 and then attempting to manage a social life whilst making sure I get enough sleep to get up again the next day, I’ve not had any time to blog. BUT I’ve finally settled into it all and I’m hoping to start getting my posts back up and running.
I shall be posting soon 🙂
Scream’s Yellow Card
Being into Consumer Psychology I’m not supposed to be fooled by loyalty cards, but I’ve got to say I’m obsessed with this little beauty!!

When me and my uni buddies go out for lunch in Bangor, we always discuss where to go and we always end up at the same place pretty much every single time, a pub called “Yellow”. Funny thing is.. the pub’s name isn’t even “Yellow” it’s actually called.. “The Old Glan” (or “Ye Hen Glan” for the Welsh) but I don’t think anyone has ever called it that, or even know that’s its name for that matter.
I originally thought the reason everyone calls the pub “Yellow” is because the outside of the building is yellow, but turns out it’s because it is part of the student-orientated pub chain “Scream” which is the creator of the yellow card!
So what’s so great about this little card and why does it work so well??
Well card owners are able to get 50% off food. Yes, that’s right, HALF PRICE FOOD!! So you can get a meal for like £2/3. Bargain. Obviously this is great for poor little students who don’t have much money (who probably shouldn’t be blowing their loans on pub grub…). If that’s not good enough, you can even get something like 25% off drinks (draughts and certain spirits).
So get the students in for lunch in the day time and provide them with a meal for a couple of quid then you’ve got them all happy, loyal and willing to come back in the evening for drinks!! I’m a prime example of a loyal customer as I still like to go there in the evening for drinks despite the offer not applying to the drinks I buy.
Another clever tactic that Scream’s company use is by placing the pubs close to universities. Like I said, it’s a student-orientated pub chain so it makes sense to be close to a uni as that’s where the students are. But not only are students going to be tempted to eat there due to the Yellow-card scheme but by putting it close to the uni’s facilities then they’re going to be even more tempted. This is more likely going to make consumers go there rather than having to walk further to some other pub, they can just pop there during lecture breaks and what not. Oh oh, also they offer free WiFi, to tempt students in to do work whilst they enjoy their £2 lunch.
I’d definitely recommend eating and drinking at Yellow to any new student joining Bangor this year. Make sure you get yourself a yellow card!
Despicable Me 2
Here’s one for the Despicable Me Fans!!
An interesting way to promote and get consumers excited for a new animated film.. interview a ‘real life’ cartoon character haha (This is Steve Carell dressed up as his character Gru from Despicable me talking about the new movie).
Sorry I don’t have chance to write much for this post as I’m rehearsing for a presentation I need to give at uni tomorrow.. but thought it was too good not to share. Drop me a comment if you have any thoughts on how or why you think this is a good (or bad) idea for promoting a new film.

Share a Coke
I know I may seem a little late with this “Share a Coke” blog as it’s been going for a couple of weeks, but if I’m honest the reason I haven’t wrote one already is because I have read so many other blogs on this topic and I thought everything had been covered. But after having a conversation about these bottles with pretty much everyone I know, I thought I had to have my say!!
Just a brief explanation for those who may not know what I’m rambling on about: Coke have replaced their iconic brand name with the top 150 most popular names in the UK. The chosen names are on individual 500ml and 375ml bottles of Coca-Cola, Diet Coke and Coke Zero.
At first I thought it was a great idea, seeing people going crazy in shops searching for a particular named Coke. I also saw loads of people complaining on Facebook or Twitter that they wanted a Coke with their name on. Then I saw the people who had managed to successfully buy or receive a Coke with their name on, post their photos on to Facebook. Such as my friend, Lisa, who was bought this bottle of Coke Zero as a gift:

Before this genius marketing technique it is unlikely that people would have thought “Lisa (or whoever) would really like a Coke Zero, I’ll buy it for her” whilst out shopping. Usually you would just purchase this size bottle if you wanted a quick drink when you were out and about, so in terms of marketing I thought Coke had done a fantastic job with everyone getting excited and wanting to purchase bottles so they could share with their friends and family.
I did a bit of research (MAJOR scientific here..) I asked a whopping 6 people what made them want a bottle of coke with their name on. They said it was just because of the novelty, the quirkiness, a bit of fun and because everyone else was showing off their new and personal Coke they wanted to join in too, even if they weren’t big Coke drinkers! Some people said that they wouldn’t go out purposely looking for a Coke with their name on, but if they were choosing a drink and couldn’t decide, they may be influenced to buy a Coke instead of something else if they saw their name. And this is exactly it, people have ALWAYS loved name gifts (mugs, keyrings, signs for your bedroom door etc) and the reason for this is because you get the feeling of belonging, ownership and pride when you own something like this.
But it was today when things changed. I was at uni doing some work when my friend, Dave, came and joined me. He had just come from Asda and had a bottle of Coke with him.. I picked up the Coke thinking “he’s bound to have Dave on it”.. when I was surprised to see this:

MICHAEL? Who is Michael? This shocked me that he would have chosen “Michael” when I knew I had seen “Dave” on the Coke bottles.
Dave told me he was going to buy a Coke regardless, as he would usually buy Coke anyway, but when he got to the stall he couldn’t help but become frustrated that he couldn’t see his name. He said he didn’t want to look stupid shifting through all the bottles to find his name, so he picked up the first one that was “similar”. He said there were lots of bottles at the front with girls’ names on.. and he would feel silly buying a bottle with a girl’s name. So he went for the next best thing.
Another thing I came across when talking to people about this, is that some people can find this whole name thing a bit embarrassing and actually purposely go out of their way to buy a Pepsi or some other alternative to Coke to avoid looking like they had fallen for this marketing trick.
So Coke may be encouraging people who don’t usually drink Coke to buy more bottles, but are they risking losing regular Coke users by frustrating and even embarrassing them???
But overall… despite it may be frustrating and a little embarrassing for some shoppers, I still think it’s a great idea and it’s just a bit of fun for the majority of consumers! And just in case you were wanting to buy me a bottle of Coke, unsurprisingly “Sinae” isn’t on the bottles. You’ll have to wait until the summer when Coke are going to do personalised bottles.. or just resort to buying me chocolate with my name on instead 😉
